Een origineel als PDF-bestand scannen met ingesloten tekstgegevens
Als u in een PDF-weergaveprogramma tekst wilt kunnen zoeken en kopiëren, kunt u tekstgegevens insluiten in een PDF die op basis van de gescande gegevens is gemaakt (OCR-functie).
U kunt deze functie ook gebruiken voor een PDF-bestand in PDF met hoge compressie of PDF/A-indeling.

Voor deze functie heeft u de optionele OCR-eenheid nodig.
U kunt de OCR-functie in de volgende gevallen gebruiken:
[TIFF/JPEG] of [TIFF] als het bestandstype is geselecteerd.
Als [100 dpi] is geselecteerd als de resolutie.
Als de WSD- of DSM-bestemmingslijst gebruikt wordt.
Op apparaten met RICOH Always Current Technology v1. 1 of ouder
 Druk op [Scanner] op het Home-scherm.
Druk op [Scanner] op het Home-scherm.
 Plaats het origineel in de scanner.
Plaats het origineel in de scanner.
 Druk op [Verzendinstellingen] op het scannerscherm.
Druk op [Verzendinstellingen] op het scannerscherm.
 Druk op [Bestandstype]
Druk op [Bestandstype]![]() [Overige].
[Overige].

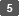 Druk op [PDF (enkele pagina)] wanneer u een PDF met slechts één pagina maakt en druk op [PDF (meerdere pagina's)] wanneer u een PDF met meerdere pagina's maakt.
Druk op [PDF (enkele pagina)] wanneer u een PDF met slechts één pagina maakt en druk op [PDF (meerdere pagina's)] wanneer u een PDF met meerdere pagina's maakt.
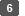 Vink het selectievakje [OCR] aan en geef aan hoe u OCR uitvoert bij "Gedetailleerde instellingen PDF".
Vink het selectievakje [OCR] aan en geef aan hoe u OCR uitvoert bij "Gedetailleerde instellingen PDF".
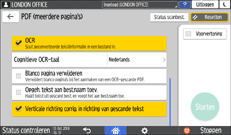
Cognitieve OCR-taal: Selecteer een taal die dezelfde is als de taal in het te scannen origineel.
Blanco pagina verwijderen: Bij het maken van een PDF-bestand worden lege pagina's uit de gescande gegevens verwijderd.
Opgeh. tekst aan best.naam toev.: Een teksttekenreeks waarvan wordt bepaald dat deze het meest geschikt is als bestandsnaam, wordt automatisch geëxtraheerd en aan de bestandsnaam toegevoegd. De teksttekenreeks wordt uit de eerste pagina van de gescande gegevens geëxtraheerd. Als er geen tekst op de eerste pagina staat, wordt er geen tekenreeks aan de bestandsnaam toegevoegd.
Verticale richting corrig. in richting van gescande tekst: De verticale afdrukrichting van het origineel wordt bepaald op basis van de afdrukrichting van tekens die door het OCR-proces worden herkend.
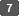 Geef de afbeeldingskwaliteit op bij Origineeltype.
Geef de afbeeldingskwaliteit op bij Origineeltype.
Om de nauwkeurigheid van de herkenning te verbeteren, selecteert u [Zwart-wit: Tekst].
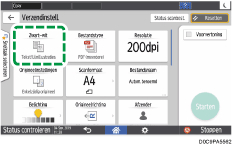
 Als u het gescande document naar een e-mailadres wilt verzenden, drukt u op [Afzender] en geeft u vervolgens de afzender op.
Als u het gescande document naar een e-mailadres wilt verzenden, drukt u op [Afzender] en geeft u vervolgens de afzender op.
 Geef de bestemming op en druk op [Starten].
Geef de bestemming op en druk op [Starten].

De verticale afdrukrichting van een bijna lege pagina wordt mogelijk niet correct vastgesteld.
Wanneer u naar een tekenreeks zoekt in een met een tekst ingesloten PDF-bestand, kunt u de tekenreeks waarnaar u zoekt gemakkelijker vinden door de zoekinstelling op te geven om vormen met halve en volledige breedte te negeren.
Afhankelijk van de grootte of resolutie van het origineel kan het langer duren om de volgende pagina te scannen.
Met de OCR-functie kunnen teksten van maximaal 40.000 tekens per pagina worden verwerkt.
De OCR-functie kan de volgende talen herkennen:
Engels, Duits, Frans, Italiaans, Spaans, Nederlands, Portugees, Pools, Zweeds, Fins, Hongaars, Noors, Deens, Japans.
De uiteindelijke resolutie kan minder dan 200 dpi zijn als een afbeelding op 200 dpi gescand wordt of een hogere resolutie wordt minder door de reproductieverhouding op te geven. U kunt de OCR-instellingen van dergelijke documenten toepassen, maar dit kan tot verminderde nauwkeurigheid van de tekstherkenning leiden.
Afhankelijk van de tekenvormen of -typen, kan het zijn dat tekens niet herkend worden.
Een PDF-bestand zonder ingevoegde tekst ontstaat als de gescande pagina geen paragraaf bevat die herkend kan worden als tekens.
Er wordt geen PDF-bestand gegenereerd als alle pagina's in een document als lege pagina's worden herkend. Zorg er in dat geval voor dat de originelen op de goede manier zijn ingesteld en probeer het opnieuw.
Een blanco pagina of het onderste en bovenste gedeelte van een pagina wordt misschien niet correct herkend als de gescande pagina vlekken heeft of een afbeelding heeft op de achterkant van de pagina die doorschijnt.
Er worden geen lettertypen geïdentificeerd terwijl de OCR-functie wordt toegepast om te scannen. Als de breedtes van de afgedrukte of ingevoegde tekens verschillen, kan het zijn dat de positie van de ingevoegde tekst niet overeenkomt met de afgedrukte tekst op de gescande pagina.
Op apparaten waarop RICOH Always Current Technology v1.2 of hoger is geïmplementeerd
Druk op [Scanner] op het Home-scherm.
Plaats het origineel in de scanner.
Druk op [Verzendinstellingen] op het scannerscherm.
Druk op [Bestandstype]![]() [Overige].
[Overige].

Druk op [PDF], [Hoge comp. PDF] of [PDF/A].
Druk op [OCR-instellingen] en geef op hoe OCR moet worden uitgevoerd.
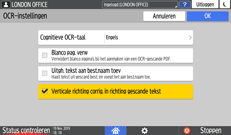
Cognitieve OCR-taal: Selecteer een taal die dezelfde is als de taal in het te scannen origineel.
Blanco pagina verwijderen: Bij het maken van een PDF-bestand worden lege pagina's uit de gescande gegevens verwijderd.
Opgeh. tekst aan best.naam toev.: Een teksttekenreeks waarvan wordt bepaald dat deze het meest geschikt is als bestandsnaam, wordt automatisch geëxtraheerd en aan de bestandsnaam toegevoegd. De teksttekenreeks wordt uit de eerste pagina van de gescande gegevens geëxtraheerd. Als er geen tekst op de eerste pagina staat, wordt er geen tekenreeks aan de bestandsnaam toegevoegd.
Verticale richting corrig. in richting van gescande tekst: De verticale afdrukrichting van het origineel wordt bepaald op basis van de afdrukrichting van tekens die door het OCR-proces worden herkend.
Klik op [OK].
Geef de afbeeldingskwaliteit op bij [Origineeltype].
Om de nauwkeurigheid van de herkenning te verbeteren, selecteert u [Zwart-wit: Tekst].
Als u het gescande document naar een e-mailadres wilt verzenden, drukt u op [Afzender] en geeft u vervolgens de afzender op.
 Geef de bestemming op en druk op [Starten]
Geef de bestemming op en druk op [Starten]
De verticale afdrukrichting van een bijna lege pagina wordt mogelijk niet correct vastgesteld.
Wanneer u naar een tekenreeks zoekt in een met een tekst ingesloten PDF-bestand, kunt u de tekenreeks waarnaar u zoekt gemakkelijker vinden door de zoekinstelling op te geven om vormen met halve en volledige breedte te negeren.
Afhankelijk van de grootte of resolutie van het origineel kan het langer duren om de volgende pagina te scannen.