Escaneo de un original como archivo PDF con datos de texto integrados
Para permitir realizar búsquedas en texto y copiar texto en una aplicación de visualización de PDF, puede integrar datos de texto en un PDF creado a partir de los datos escaneados (función de OCR).
También puede usar esta función con archivos PDF cuyo formato sea PDF de alta compresión o PDF/A.

La unidad opcional de OCR es necesaria para usar esta función.
No es posible utilizar la función OCR en los siguientes casos:
[TIFF/JPEG] o [TIFF] está seleccionado como tipo de archivo.
[100 dpi] está seleccionado como la resolución.
Cuando se usa la lista de destinos WSD o DSM.
En máquinas en las que se haya instalado el RICOH Always Current Technology v1. 1 o versiones anteriores
 Pulse [Escáner] en la pantalla de inicio.
Pulse [Escáner] en la pantalla de inicio.
 Coloque el original en el escáner.
Coloque el original en el escáner.
 Pulse [Enviar ajustes] en la pantalla del escáner.
Pulse [Enviar ajustes] en la pantalla del escáner.
 Pulse [Tipo de archivo]
Pulse [Tipo de archivo]![]() [Otros].
[Otros].

 Pulse [PDF (Una página)] cuando cree un PDF con una sola página y pulse [PDF(Varias págs.)] cuando cree un PDF con varias páginas.
Pulse [PDF (Una página)] cuando cree un PDF con una sola página y pulse [PDF(Varias págs.)] cuando cree un PDF con varias páginas.
 Marque la casilla de verificación [OCR] y especifique cómo desea realizar el OCR en "Aj. detallados PDF".
Marque la casilla de verificación [OCR] y especifique cómo desea realizar el OCR en "Aj. detallados PDF".
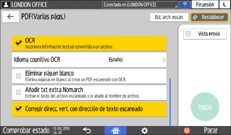
Idioma cognitivo OCR: seleccione el idioma usado en el original que desee escanear.
Eliminar página en blanco: se quitan las páginas en blanco de los datos escaneados al crear un archivo PDF.
Añadir txt extr.a Nom.arch: se extrae la cadena de texto que se considera la más adecuada para ser el nombre del archivo y se añade automáticamente al nombre del archivo. La cadena de texto se extrae de la primera página de los datos escaneados. Si la primera página no contiene texto, no se añade ninguna cadena al nombre del archivo.
Corregir direcc. vert. con dirección de texto escaneado: la orientación vertical del original se determina en función de la orientación de los caracteres reconocidos sucesivamente por el proceso de OCR.
 Especifique la calidad de la imagen en Tipo original.
Especifique la calidad de la imagen en Tipo original.
Para mejorar la precisión del reconocimiento, seleccione [Blanco y Negro: Texto].
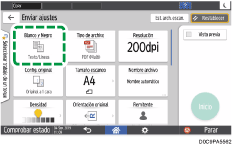
 Para enviar el documento escaneado a una dirección de email, pulse [Remitente] y, a continuación, especifique el remitente.
Para enviar el documento escaneado a una dirección de email, pulse [Remitente] y, a continuación, especifique el remitente.
 Especifique el destino y pulse [Inicio].
Especifique el destino y pulse [Inicio].

Es posible que la orientación vertical de una página casi en blanco no se determine correctamente.
Cuando busque una cadena en un archivo PDF con texto integrado, podrá encontrarla más fácilmente si especifica un ajuste de búsqueda que ignore formas de ancho medio y total.
Iniciar el escaneo de la página siguiente puede tardar más tiempo en función del tamaño o la resolución del original.
La función de OCR puede procesar textos de hasta 40.000 caracteres por página.
La función de OCR puede reconocer los siguientes idiomas:
Inglés, alemán, francés, italiano, español, neerlandés, portugués, polaco, sueco, finlandés, húngaro, noruego, danés, japonés.
Si especifica una escala de reproducción para reducir una imagen escaneada a 200 dpi o una resolución superior, es posible que la resolución efectiva sea inferior a 200 dpi. Puede aplicar la función OCR en dichos casos, pero la precisión del reconocimiento de texto puede deteriorarse.
En función de los tipos o formas de los caracteres, puede que no se reconozcan correctamente.
Se generará un archivo PDF sin texto incrustado si la página escaneada no contiene ninguna sección que pueda reconocerse como caracteres.
No se generará ningún archivo PDF si se determina que todas las páginas de un documento son páginas en blanco. Si esto ocurre, asegúrese de establecer los originales correctamente y vuelva a intentarlo.
Puede que no se reconozca correctamente una página en blanco o la parte inferior y superior de una página si la página escaneada tiene borrones o manchas, o si se transparenta la parte posterior de esa página.
No se identifican caras de tipos cuando se aplica la función OCR al escaneo. Si las anchuras de los caracteres impresos e incrustados difieren, la posición del texto incrustado puede no coincidir con la del texto impreso en las páginas escaneadas.
En máquinas con RICOH Always Current Technology v1.2 o posterior
Pulse [Escáner] en la pantalla de inicio.
Coloque el original en el escáner.
Pulse [Enviar ajustes] en la pantalla del escáner.
Pulse [Tipo de archivo]![]() [Otros].
[Otros].

Pulse [PDF], [PDF alta compresión] o [PDF/A].
Pulse [Ajustes OCR], y especifique cómo realizar un OCR.
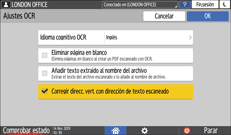
Idioma cognitivo OCR: seleccione el idioma usado en el original que desee escanear.
Eliminar página en blanco: se quitan las páginas en blanco de los datos escaneados al crear un archivo PDF.
Añadir txt extr.a Nom.arch: se extrae la cadena de texto que se considera la más adecuada para ser el nombre del archivo y se añade automáticamente al nombre del archivo. La cadena de texto se extrae de la primera página de los datos escaneados. Si la primera página no contiene texto, no se añade ninguna cadena al nombre del archivo.
Corregir direcc. vert. con dirección de texto escaneado: la orientación vertical del original se determina en función de la orientación de los caracteres reconocidos sucesivamente por el proceso de OCR.
Haga clic en [OK].
Especifique la calidad de la imagen en [Tipo original].
Para mejorar la precisión del reconocimiento, seleccione [Blanco y Negro: Texto].
Para enviar el documento escaneado a una dirección de email, pulse [Remitente] y, a continuación, especifique el remitente.
 Especifique el destino y pulse [Inicio]
Especifique el destino y pulse [Inicio]
Es posible que la orientación vertical de una página casi en blanco no se determine correctamente.
Cuando busque una cadena en un archivo PDF con texto integrado, podrá encontrarla más fácilmente si especifica un ajuste de búsqueda que ignore formas de ancho medio y total.
Iniciar el escaneo de la página siguiente puede tardar más tiempo en función del tamaño o la resolución del original.