Scanning an Original as a PDF File with Embedded Text Data
To enable searching and copying of text in a PDF viewing application, you can embed text data in a PDF created from the scanned data (OCR function).
You can also use this function for a PDF file in the high-compression PDF or PDF/A format.

The optional OCR unit is required to use this function.
On machines implemented with RICOH Always Current Technology v1.1 or before
 Press [Scanner] on the Home screen.
Press [Scanner] on the Home screen.
 Place the original on the scanner.
Place the original on the scanner.
 Press [Send Settings] on the scanner screen.
Press [Send Settings] on the scanner screen.
 Press [File Type]
Press [File Type]![]() [Others].
[Others].

 Press [PDF (Single Page)] when creating a PDF with only one page, and press [PDF (Multi-page)] when creating a PDF with multiple pages.
Press [PDF (Single Page)] when creating a PDF with only one page, and press [PDF (Multi-page)] when creating a PDF with multiple pages.
 Select the [OCR] check box and specify how to perform OCR in "PDF Detailed Settings".
Select the [OCR] check box and specify how to perform OCR in "PDF Detailed Settings".
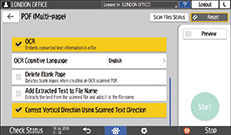
OCR Cognitive Language: Select a language that is the same as the language used in the original to scan.
Delete Blank Page: Blank pages are removed from the scanned data when creating a PDF file.
Add Extracted Text to File Name: A text string that is determined to be most appropriate as the file name is extracted and appended to the file name automatically. The text string is extracted from the first page of the scanned data. If no text is contained on the first page, no string is appended to the file name.
Correct Vertical Direction Using Scanned Text Direction: The vertical orientation of the original is determined based on the orientation of characters that are successfully recognized by the OCR process.
 Specify the image quality in [Original Type].
Specify the image quality in [Original Type].
To improve the recognition accuracy, select [Black & White: Text].
 To send the scanned document to an e-mail address, press [Sender] and then specify the sender.
To send the scanned document to an e-mail address, press [Sender] and then specify the sender.
 Specify the destination, and press [Start]
Specify the destination, and press [Start]

The vertical orientation of a page that is nearly blank may not be determined correctly.
When searching for a string in a text-embedded PDF file, you can find the string you are searching for more easily by specifying the search setting to ignore halfwidth and fullwidth forms.
The time to start scanning the next page may take longer depending on the original size or resolution.
On machines implemented with RICOH Always Current Technology v1.2 or later
Press [Scanner] on the Home screen.
Place the original on the scanner.
Press [Send Settings] on the scanner screen.
Press [File Type]![]() [Others].
[Others].

Press [PDF], [High Comp. PDF], or [PDF/A].
Press [OCR Settings], and specify how to perform OCR.
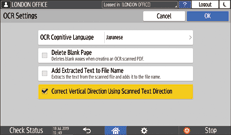
OCR Cognitive Language: Select a language that is the same as the language used in the original to scan.
Delete Blank Page: Blank pages are removed from the scanned data when creating a PDF file.
Add Extracted Text to File Name: A text string that is determined to be most appropriate as the file name is extracted and appended to the file name automatically. The text string is extracted from the first page of the scanned data. If no text is contained on the first page, no string is appended to the file name.
Correct Vertical Direction Using Scanned Text Direction: The vertical orientation of the original is determined based on the orientation of characters that are successfully recognized by the OCR process.
Specify the image quality in [Original Type].
To improve the recognition accuracy, select [Black & White: Text].
To send the scanned document to an e-mail address, press [Sender] and then specify the sender.
Specify the destination, and press [Start]
The vertical orientation of a page that is nearly blank may not be determined correctly.
When searching for a string in a text-embedded PDF file, you can find the string you are searching for more easily by specifying the search setting to ignore halfwidth and fullwidth forms.
The time to start scanning the next page may take longer depending on the original size or resolution.