Numériser un original sous forme de fichier PDF avec des données de texte intégrées
Pour permettre la recherche et la copie de texte dans une application d’affichage de PDF, vous pouvez intégrer les données de texte dans un PDF créé à partir des données numérisées (fonction OCR).
Vous pouvez également utiliser cette fonction pour un fichier PDF au format PDF Haute compression ou PDF/A.

L’unité OCR optionnelle est indispensable pour utiliser cette fonction.
Vous ne pouvez pas utiliser la fonction OCR dans les cas suivants :
[TIFF/JPEG] ou [TIFF] est sélectionné comme type de fichier.
[100 dpi] est sélectionné comme résolution.
Lorsque la liste de destinations WSD ou DSM est utilisée.
Sur les appareils dotés de RICOH Always Current Technology v1. 1 ou d'une version antérieure
 Appuyez sur [Scanner] sur l’écran d'Accueil.
Appuyez sur [Scanner] sur l’écran d'Accueil.
 Placez l'original sur le scanner.
Placez l'original sur le scanner.
 Appuyez sur [Paramètres d'envoi] sur l’écran du scanner.
Appuyez sur [Paramètres d'envoi] sur l’écran du scanner.
 Appuyez sur [Type de fichier]
Appuyez sur [Type de fichier]![]() [Autres].
[Autres].

 Appuyez sur [PDF (Simple page)] lorsque vous créez un PDF composé d’une seule page et appuyez sur [PDF (Multipages)] lorsque vous créez un PDF composé de plusieurs pages.
Appuyez sur [PDF (Simple page)] lorsque vous créez un PDF composé d’une seule page et appuyez sur [PDF (Multipages)] lorsque vous créez un PDF composé de plusieurs pages.
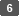 Cochez la case [OCR] et spécifiez comment réaliser l’OCR dans "Paramètres détaillés PDF".
Cochez la case [OCR] et spécifiez comment réaliser l’OCR dans "Paramètres détaillés PDF".
Langue de reconnaissance OCR : sélectionnez la même langue que celle utilisée dans l’original à numériser.
Supprimer page vierge : les pages vierges sont supprimées des données numérisées lors de la création d’un fichier PDF.
Ajout.texte extrait au nom de fichier : une chaîne de texte déterminée comme la plus appropriée en tant que nom de fichier est automatiquement extraite et ajoutée au nom de fichier. La chaîne de texte est extraite de la première page de données numérisées. Si la première page ne comporte pas de texte, aucune chaîne n’est ajoutée au nom de fichier.
Corriger orient. vertic. à l'aide de l'orient. du txt numér. : l’orientation verticale de l’original est déterminée en fonction de l’orientation des caractères reconnus par le processus d’OCR.
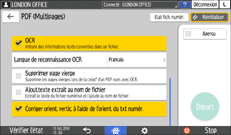
 Spécifiez la qualité d’image dans Type d'original.
Spécifiez la qualité d’image dans Type d'original.
Pour améliorer la précision de la reconnaissance, sélectionnez [Noir & Blanc : Texte].
 Pour envoyer le document numérisé vers une adresse e-mail, appuyez sur [Expéditeur] et spécifiez l'expéditeur.
Pour envoyer le document numérisé vers une adresse e-mail, appuyez sur [Expéditeur] et spécifiez l'expéditeur.
 Définissez le destinataire, puis appuyez sur [Départ].
Définissez le destinataire, puis appuyez sur [Départ].

Il se peut que l’orientation verticale d’un page presque vierge ne soit pas déterminée correctement.
Lorsque vous recherchez une chaîne dans un fichier PDF intégrant du texte, vous pouvez trouver la chaîne que vous recherchez beaucoup plus facilement en spécifiant le paramètre de recherche indiquant d’ignorer les formes à demie et pleine chasse.
Le temps nécessaire à numériser la page suivante peut être plus long en fonction du format ou de la résolution d'origine.
La fonction OCR peut traiter des textes jusqu'à 40 000 caractères par page.
La fonction OCR peut reconnaître les langues suivantes :
Anglais, Allemand, Français, Italien, Espagnol, Néerlandais, Portugais, Polonais, Suédois, Finnois, Hongrois, Norvégien, Danois, Japonais.
La résolution réelle pourrait être inférieure à 200 dpi si une image numérisée à 200 dpi ou à un résolution supérieure est réduite lors de la définition du ratio de reproduction. Vous pouvez utiliser la fonction OCR dans ce cas, mais la précision de la reconnaissance de texte peut être réduite.
Selon les types ou formes des caractères, certains pourraient ne pas être reconnus correctement.
Un fichier PDF sans texte inséré est généré si la page numérisée ne contient pas de section qui puisse être reconnue comme des caractères.
Aucun fichier PDF n'est généré si toutes les pages d'un document sont déterminées comme des pages vierges. Si cela se produit, assurez-vous de positionner les originaux correctement et essayez à nouveau.
Une page blanche ou le haut et le bas de la page pourraient ne pas être facilement reconnaissables si la page numérisée présente des bavures ou des tâches ou si une image du verso de la page peut se voir sur le recto.
Les pages sans type sont identifiées lorsque la fonction OCR est appliquée à la numérisation. Si les largeurs des caractères imprimés et insérés sont différentes, la position du texte inséré pourrait ne pas correspondre à celle du texte imprimé sur la page numérisée.
Sur les machines équipées de RICOH Always Current Technology v1.2 ou une version ultérieure
Appuyez sur [Scanner] sur l’écran d'Accueil.
Placez l'original sur le scanner.
Appuyez sur [Paramètres d'envoi] sur l’écran du scanner.
Appuyez sur [Type de fichier]![]() [Autres].
[Autres].

Appuyez sur [PDF], [PDF haute compr.], ou [PDF/A].
Appuyez sur [Paramètres OCR] et spécifiez comment réaliser l'OCR.
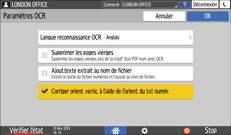
Langue de reconnaissance OCR : sélectionnez la même langue que celle utilisée dans l’original à numériser.
Supprimer page vierge : les pages vierges sont supprimées des données numérisées lors de la création d’un fichier PDF.
Ajout.texte extrait au nom de fichier : une chaîne de texte déterminée comme la plus appropriée en tant que nom de fichier est automatiquement extraite et ajoutée au nom de fichier. La chaîne de texte est extraite de la première page de données numérisées. Si la première page ne comporte pas de texte, aucune chaîne n’est ajoutée au nom de fichier.
Corriger orient. vertic. à l'aide de l'orient. du txt numér. : l’orientation verticale de l’original est déterminée en fonction de l’orientation des caractères reconnus par le processus d’OCR.
Cliquez sur [OK].
Spécifiez la qualité d’image dans [Type d'original].
Pour améliorer la précision de la reconnaissance, sélectionnez [Noir & Blanc : Texte].
Pour envoyer le document numérisé vers une adresse e-mail, appuyez sur [Expéditeur] et spécifiez l'expéditeur.
 Définissez le destinataire, puis appuyez sur [Départ]
Définissez le destinataire, puis appuyez sur [Départ]
Il se peut que l’orientation verticale d’un page presque vierge ne soit pas déterminée correctement.
Lorsque vous recherchez une chaîne dans un fichier PDF intégrant du texte, vous pouvez trouver la chaîne que vous recherchez beaucoup plus facilement en spécifiant le paramètre de recherche indiquant d’ignorer les formes à demie et pleine chasse.
Le temps nécessaire à numériser la page suivante peut être plus long en fonction du format ou de la résolution d'origine.