Сканирование оригинала в виде PDF-файла со встроенными текстовыми данными
Чтобы разрешить поиск и копирование текста в приложении для просмотра PDF-файлов, можно вставить текстовые данные в PDF-файл, созданный из отсканированных данных (функция OCR).
Эту функцию также можно использовать для файлов формата PDF с высокой степенью сжатия или PDF/A.

Для использования этой функции требуется дополнительное устройство OCR.
Функцию оптического распознавания символов невозможно использовать в следующих случаях:
В качестве типа файла выбран [TIFF/JPEG] или [TIFF].
В качестве разрешения выбрано [100 т/д].
Если используется список адресатов WSD или DSM.
На аппаратах с приложением RICOH Always Current Technology v1. 1 или предыдущей версии
 На Начальном экране нажмите [Сканер].
На Начальном экране нажмите [Сканер].
 Поместите оригинал в сканер.
Поместите оригинал в сканер.
 На экране сканера нажмите [Настройки отправки].
На экране сканера нажмите [Настройки отправки].
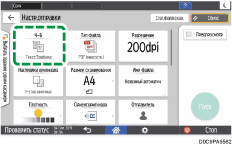
 Нажмите [Тип файла]
Нажмите [Тип файла]![]() [Другое].
[Другое].

 Нажмите [PDF (Одностраничный)] при создании PDF-файла из одной страницы и нажмите [PDF (Многостраничный)] при создании PDF-файла из нескольких страниц.
Нажмите [PDF (Одностраничный)] при создании PDF-файла из одной страницы и нажмите [PDF (Многостраничный)] при создании PDF-файла из нескольких страниц.
 Поставьте отметку в поле [OCR] и укажите, как выполнить OCR, в блоке "Расширенные настройки PDF".
Поставьте отметку в поле [OCR] и укажите, как выполнить OCR, в блоке "Расширенные настройки PDF".
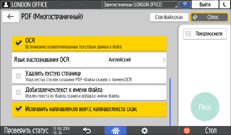
Язык распознавания OCR: выберите язык, совпадающий с языком оригинала для сканирования.
Удалить пустую страницу: пустые страницы удаляются из отсканированных данных при создании PDF-файла.
Доб.извлечен.текст к имени файла: текстовая строка, которая лучше всего соответствует имени файла, автоматически извлекается и вставляется в имя файла. Текстовая строка извлекается из первой страницы отсканированных данных. Если первая страница не содержит текста, то строка не добавляется в имя файла.
Исправить направлен.по верт.с направл.текста скан.: ориентация оригинала по вертикали определяется ориентацией символов, успешно распознанных OCR-процессом.
 Укажите качество изображения в блоке Тип оригинала.
Укажите качество изображения в блоке Тип оригинала.
Чтобы повысить точность распознавания, выберите [Ч-Б: Текст].
 Чтобы отправить отсканированный документ по электронной почте, нажмите [Отправитель] и задайте имя отправителя.
Чтобы отправить отсканированный документ по электронной почте, нажмите [Отправитель] и задайте имя отправителя.
 Укажите адресата и нажмите клавишу [Пуск].
Укажите адресата и нажмите клавишу [Пуск].

Ориентация по вертикали почти пустой страницы может определяться неправильно.
При поиске текстовой строки, добавленной в PDF-файл, можно найти искомую строку намного проще, если указать параметр поиска, позволяющий пропускать формы с половиной ширины и формы с полной шириной.
Сканирование следующей страницы может начаться позже в зависимости от размера оригинала и разрешения.
Функция OCR может обрабатывать тексты объемом до 40 000 символов на каждой странице.
Функция OCR может распознавать следующие языки:
Английский, немецкий, французский, итальянский, испанский, голландский, португальский, польский, шведский, финский, венгерский, норвежский, датский, японский.
При сканировании изображения в разрешении 200 точек на дюйм эффективное разрешение может быть менее 200 точек на дюйм из-за применения коэффициента масштабирования. В этих случаях можно применить настройки OCR, но качество распознавания может ухудшиться.
Некоторые формы и типы символов могут не распозноваться корректно.
Если сканируемая страница не содержит распознанных как текст секций, будет создан PDF-файл без встроенного текста.
Файл PDF не будет создан, если все страницы документа будут определены как пустые. В этом случае проверьте правильность расположения оригиналов и попробуйте еще раз.
Пустая страница или вехняя и нижняя часть страницы могут не распознаваться корректно, если на отсканированной странице есть пятна или следы грязи, а также если сквозь нее просвечивает изображение с обратной стороны.
Если при сканировании включена функция распознавания, типы не определяются. Если ширина встроенных и печатаемых символов различается, положение встроенного текста может не совпадать с отпечатанным на отсканированной странице.
На машинах с RICOH Always Current Technology v1.2 или более поздней версии
На Начальном экране нажмите [Сканер].
Поместите оригинал в сканер.
На экране сканера нажмите [Настройки отправки].
Нажмите [Тип файла]![]() [Другое].
[Другое].

Выберите [PDF], [PDF высокого сжатия] или [PDF/A].
Нажмите [Настройки OCR] и укажите способ выполнения распознавания.
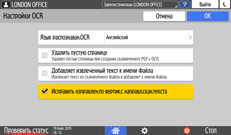
Язык распознавания OCR: выберите язык, совпадающий с языком оригинала для сканирования.
Удалить пустую страницу: пустые страницы удаляются из отсканированных данных при создании PDF-файла.
Доб.извлечен.текст к имени файла: текстовая строка, которая лучше всего соответствует имени файла, автоматически извлекается и вставляется в имя файла. Текстовая строка извлекается из первой страницы отсканированных данных. Если первая страница не содержит текста, то строка не добавляется в имя файла.
Исправить направлен.по верт.с направл.текста скан.: ориентация оригинала по вертикали определяется ориентацией символов, успешно распознанных OCR-процессом.
Нажмите [OK].
Укажите качество изображения в блоке [Тип оригинала].
Чтобы повысить точность распознавания, выберите [Ч-Б: Текст].
Чтобы отправить отсканированный документ по электронной почте, нажмите [Отправитель] и задайте имя отправителя.
 Укажите адресата и нажмите клавишу [Пуск]
Укажите адресата и нажмите клавишу [Пуск]
Ориентация по вертикали почти пустой страницы может определяться неправильно.
При поиске текстовой строки, добавленной в PDF-файл, можно найти искомую строку намного проще, если указать параметр поиска, позволяющий пропускать формы с половиной ширины и формы с полной шириной.
Сканирование следующей страницы может начаться позже в зависимости от размера оригинала и разрешения.